数据存储和数据存取
物理存储介质概述
高速缓存器(cache) 高速缓存器是最快最昂贵的储存介质。高速缓存器一般很小,由计算机系统硬件来管理它的使用。
主存储器(main memory) 主存储器是用于存放可处理的数据的储存介质。通用机器指令在主储存器上执行。如果发生电源故障或者系统崩溃,主存储器中的内容通常会丢失。
快闪存储器(flash memory) 快闪存储器不同于主存储器的地方是在电源关闭(或故障)时数据可以保存下来。
磁盘存储器(magnetic-disk storage) 用于长期联机数据存储的主要介质是磁盘。通常整个数据库都存储在磁盘上,为了能够访问数据,系统必须将数据从磁盘移动到主存储器。在完成指定的操作后,修改过的数据必须写回磁盘。磁盘存储器不会因为系统故障和系统崩溃丢失数据。磁盘存储设备本身有时有可能会发生故障,导致数据的损坏,但是发生磁盘故障的概率比发生系统崩溃的概率小很多。
光学存储器(optical storage)
光学存储器最流行的形式是光盘(Compact Disk, CD),它可以容纳大约700MB的数据,播放约80分钟。
数字视频光盘(Digital Video Disk, DVD)的每一盘面可以容纳4.7GB或8.5GB的数据。
可以用数字万能光盘(digital versatile disk)代替数字视频光盘(digital video disk)作为DVD的全称,因为DVD可以存储任何数字数据而不是仅仅视频数据。
数据通过光学的方法储存到光盘上,并通过激光器读取。磁带存储器(tape storage) 磁带存储器主要用于备份数据和归档数据。
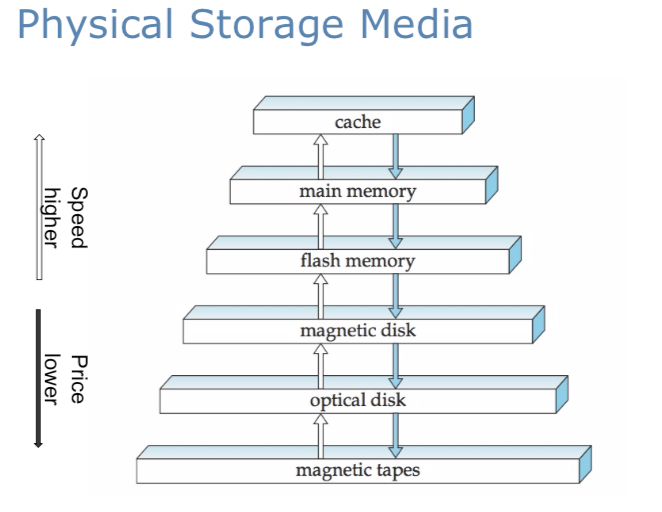
根据不同储存介质的速度和成本,可以把它们按层次结构组织起来。层次越高,这种存储介质的成本就越贵,但是速度就越快。当我们沿着层次结构向下,储存介质每比特的成本下降,但是访问时间会增加。
磁盘和闪存
磁盘的物理特性
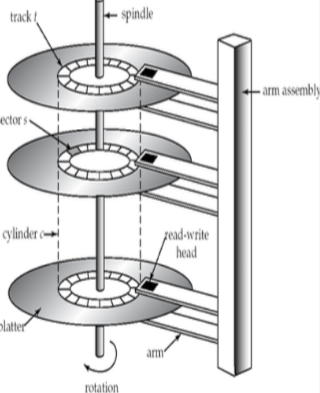
磁盘上的每一个盘片(platter)是扁平的圆盘,它的两个表面都覆盖着磁性物质,信息就记录在表面上,盘片由硬金属或玻璃制成。
盘片的表面从逻辑上划分为磁道(track),磁道又划分为扇区(sector)。扇区是从磁盘读出和写入信息的最小单位。
通过反转磁性物质化的方向,读写头(read-write head)将信息磁化存储到扇区中。磁盘的每个盘片的每一面都有一个读写头,读写头通过在盘片上移动来访问不同的磁道。一张磁盘通常包括很多个盘片,所有磁道的读写头安装在一个称为磁盘臂(disk arm)的单独装置上,并且一起移动。安装在转轴上的所有磁盘盘片和安装在磁盘臂上的所有读写头统称为磁头-磁盘装置(head-disk assembly)
因为所有盘片上读写头一起移动,所以当某一盘片的读写头在第$i$条磁道上时,所有其他盘片的读写头也都在各自盘片的第$i$条磁道上。因此,所有盘片的第$i$条磁道和在一起称为第$i$个柱面(cylinder)。
磁盘控制器(disk controller)作为计算机系统和实际的磁盘驱动器硬件之间的接口。
磁盘性能的度量
磁盘质量的主要度量指标是容量、访问时间、数据传输率和可靠性
访问时间(access time)是从发出读写请求到数据开始传输之前的时间。
Access time = Seek time + Rotational latency + (Transfer time)
寻道时间(Seek time):为了访问(即读或写)磁盘上指定扇区的数据,磁盘臂首先必须移动,以定位到正确的磁道,磁盘臂重定位的时间称为寻道时间。从最里面的磁道到最外面的磁道是最糟糕的情况。平均寻道时间(Average seek time)是寻道的平均值,如果考虑读写头开始移动和结束移动所花费的时间,平均寻道时间大约是最长寻道时间的1/2.
旋转等待时间(rotational latency time):一旦读写头到达了所需的磁道,等待访问的扇区出现在读写头下所花费的时间称为旋转等待时间。平均情况下,磁盘需要旋转半周才能使所要访问的扇区开始处于读写头的下方。因此磁盘的平均旋转等待时间是磁盘旋转一周时间的1/2。
数据传输率(data-transfer rate)是从磁盘获得数据或者向磁盘储存数据的速率。在大部分情况下,数据传输率远小于寻道时间和旋转等待时间。
磁盘块访问的优化
磁盘I/O请求是由文件系统和大多数操作系统具有的虚拟内存管理器产生的。每个请求指定了要访问的磁盘地址,这个地址是以块号的形式提供的。一个块(block)是一个逻辑单元,它包含固定数目的连续扇区。块大小在512字节到几KB之间。数据在磁盘和主储存器之间以块为单位传输。
Smaller blocks: more transfers from disk
Larger blocks: more space wasted due to partially filled blocks
磁盘臂调度(disk-arm-scheduling)算法试图把对磁道的访问按照能增加可以处理的访问数量的方式排序
电梯算法(elevator algorithm)是最常使用的算法
文件和记录的组织
文件组织(file organization)
为了减少块访问时间,我们可以按照与预期数据访问方式最接近的方式来组织磁盘上的块。例如,如果我们预计一个文件将顺序地访问,那么理想情况下我们应该使文件的所有块储存在连续的相邻柱面上。
一个数据库被映射到多个不同的文件,一个文件(file)在逻辑上组织成为记录(record)的一个序列(sequence)。这些记录映射到磁盘块(fields)。
每个文件分为定长的储存单元,称为块,块是储存分配和数据传输的基本单元。
我们需要要求每条记录包含在单个块中,换句话说,没有记录是部分包含在一个块中,部分包含在另一个块中。这个限制简化并加速数据项访问。
在关系数据库中,不同关系的远组通常具有不同的大小。把数据库映射到文件的一种方法是使用多个文件,在任意一个文件中只储存一个固定长度的记录。另一种选择是构建自己的文件,使之能够容纳多钟长度的记录。定长记录比变长记录文件更容易实现。
- 定长记录(fixed-length records)
存在的问题:
- 除非块的大小恰好是记录的倍数,否则部分记录会跨过快的边界,即一条记录的一部分储存在一个块里,另一部分储存在另一个块里,于是读写这样的一条记录需要两次块访问。分配尽可能多的记录在一个块里
- 从这个结构中删除一条记录十分困难。删除的记录所占据的空间必须由文件中的其他记录来填充,或者我们必须用一种方法标记删除的记录使得它可以被忽略。*移动记录以删除记录所释放空间的做法并不理想,因为这样做需要额外的块访问操作。
解决方案: - 在文件的开始处,我们分配一定数量的字节作为文件头(file header。文件头将包含有关文件的各种信息。到目前为止,我们需要在文件头中储存的只有内容被删除的第一个记录的地址。我们用这第一个记录来储存第二个可用记录的地址。我们可以直观的把这些储存的地址看作指针,因为他们指向一个记录的位置。
- 被删除的记录形成了一条链表,经常称为空闲链表(free list)
- 在插入一条新记录时,我们使用文件头所指向的记录,并改变文件头的指针以指向下一个可用记录。如果没有可用的空间,我们就把这条新纪录添加到文件末尾🔚。
对于定长记录文件的插入和删除是容易实现的,因为被删除的记录留出的可用空间恰好是插入记录所需要的空间。如果我们允许文件中包含不同长度的记录,这样的匹配将不再成立。插入的记录可能无法放入一条被删除记录所释放的空间中,或者只能占用这个空间的一部分。
- 变长记录(variable-length records)
一条有变长度属性的记录表示通常具有两个部分:初识部分是定长属性,接下来是变长属性。
定长属性,如数字值、日期或定长字符串,分配储存它们的值所需的字节数。
变长属性,在记录的初始部分中表示为一个对(偏移量,长度)值,其中偏移量表示在记录中该属性的数据开始的位置,长度表示变长属性的字节长度。在记录的初识定长部分之后,这些属性的值是连续储存的。
因此,无论是定长还是变长,记录初始部分储存有关每个属性的固定长度的信息。
一般用分槽的页结构(slotted-page structure)在块中组织记录,来处理在块中储存变长记录的问题。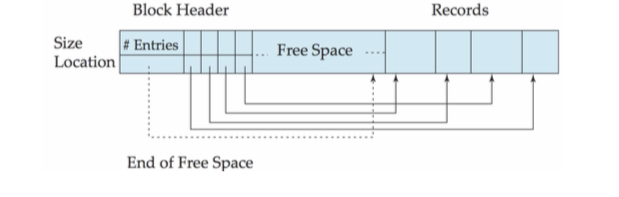
每个块的开始有一个块头,其中包含以下信息:
- 块头中记录条目的个数
- 块中空闲空间的末尾处
- 一个由包含记录位置和大小的记录条目组成的数组
实际记录从块的尾部开始连续排列。块中空闲空间是连续的,在块头数组的最后一个条目和第一条记录之间。
如果插入一条记录,在空闲空间的尾部给这条记录分配空间,并且将包含这条记录大小和位置的条目添加到块头中。
如果一条记录被删除,它所占用的空间被释放,并且它的条目被设置成被删除状态(例如这条记录的大小被设置成-1)。此外,块中在被删除记录之前的记录将被移动,使得由删除而产生的空闲空间被重用,并且所有的空闲空间仍然存在于块头数组的最后一个条目和第一条记录之间。块头中的空闲空间末尾指针也要做适当修改。只要块中有空间,使用类似的技术可以使记录增长或缩短。
大对象常常被B+树文件组织。
文件中记录的组织
- 堆文件组织(heap file organization)。一条记录可以放在文件中的任何地方,只要那个地方有空间存放这条记录。记录是没有顺序的。通常每个关系使用一个单独的文件。
- 顺序文件组织(sequential file organization)。记录根据其“搜索码”的值顺序储存。
- 散列文件组织(hashing file organization)。在每条记录的每个属性上计算一个散列函数。散列函数的结果确定了记录该放到文件的哪个块中。
通常,每个关系的记录用一个单独的文件储存。但是在多表聚簇文件组织(multitable clustering file organization)中,几个不同关系的记录储存在同一个文件中。而且,不同关系的相关记录储存在相同的块中,于是一个I/O操作可以从所有关系中取到相关的记录。
各种方式的优劣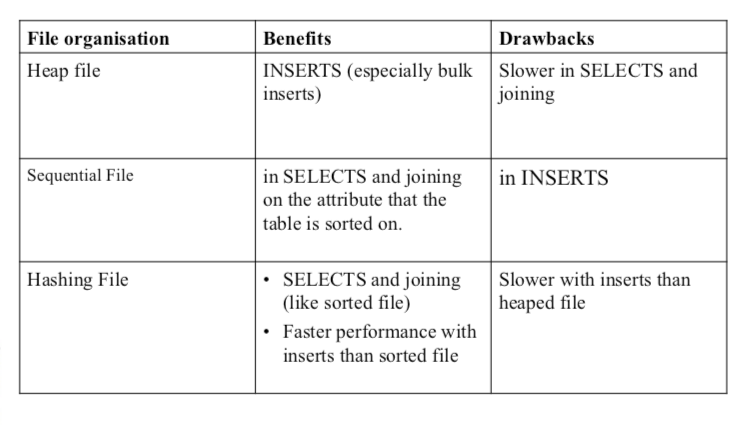
顺序文件组织
顺序文件(sequential file)是为了高效处理按某个搜索码的顺序排序的记录而设计的。为了快速地按照搜索码的顺序获取记录,我们通过指针把记录链接起来,每条记录的指针指向按搜索码顺序排列的下一条记录。此外,为了减少顺序文件处理中的快访问数,我们物理上按搜索码顺序或者尽可能地接近按搜索码顺序储存记录。
顺序文件组织形式适合于记录按排序的顺序读取,但在插入和删除记录时维护记录的物理顺序是十分困难的。
我们使用指针链表来管理删除。
插入操作则应用以下规则:
- 如果这条记录所在块中有一条空闲记录(删除后留下来的空间),就插到这里。
- 如果没有空闲空间,则新纪录要插入到一个溢出块(overflow block)中。
无论哪种情况,都要调整指针,使其能按搜索顺序把记录连接在一起。
多表聚簇文件组织
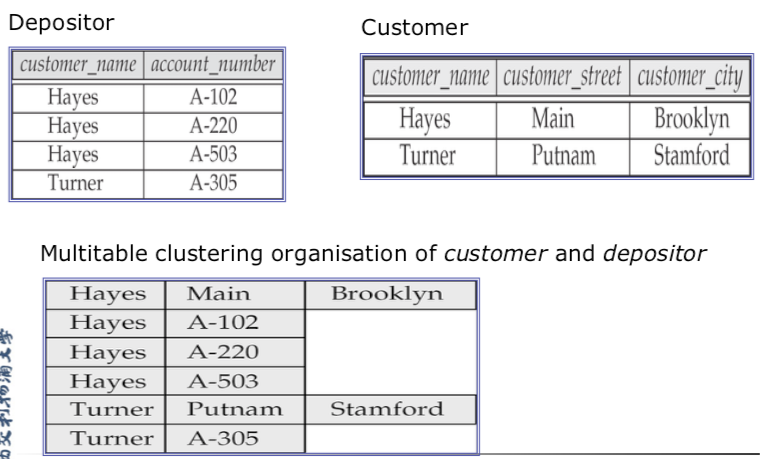
多表聚簇文件组织是一种在每一块中储存两个或更多关系的相关记录的文件结构。
这样的文件组织允许我们使用一次块的读操作来满足连接条件的记录。
但对于普通单表关系查询则会变慢
产生变化长度的记录
可以添加指针去用一种特殊的关系连接记录