DNS: 因特网的目录服务
主机的一种识别方法是用它的主机名(hostname),如cnn.com,但主机名提供了很少关于主机在因特网中的信息。因为主机名可能由不定长的字母数字组成,所以路由器很难处理。
基于上述原因,主机也可以用IP地址(IP address)进行识别。
DNS提供的服务
DNS协议是应用层协议,它使用客户机/服务器模式在通信的端系统之间运行,在通信的端系统之间通过下面的端到端运输层协议来传输DNS报文。
然而在某种意义上,DNS的作用非常不同于Web应用、文件传输应用以及电子邮件应用。不同之处在于,DNS并不直接和用户打招呼。相反,DNS为因特网上的用户应用程序以及其他软件提供一种核心功能,即将主机名转换为它们下面的IP地址。
有两种方式识别主机:通过主机名或者IP地址。人们喜欢便于记忆的主机名标示,而路由器则喜欢定长的、有着层次结构的IP结构。域名系统(Domain Name System,DNS)的主要任务就是进行主机名到IP地址转换的目录服务。
DNS是一个由分层的DNS服务器(DNS server)实现的分布式数据库。DNS是一个允许主机查询分布式数据库的应用层协议。
DNS所提供的服务:
- 主机名到IP地址的转换
- 主机别名(host aliasing)。有着复杂主机名的主机可以拥有一个或多个别名,应用程序可以调用DNS来获得主机别名对应的规范主机名及主机的IP地址。
- 邮件服务器别名(mail server aliasing)。电子邮件应用程序调用DNS,对提供的邮件服务器别名进行解析,以获得该主机的规范主机名及其IP地址。
- 负载分配(load distribution)
DNS也用在冗余的服务器(如冗余的Web服务器等)之间进行负载分配。DNS工作机理概述
DNS的一种简单设计方式是在因特网上只使用一个DNS服务器,该服务器包含所有的映射。在这种集中式设计中,客户机直接将所有查询直接发往单一的DNS服务器,同时该DNS服务器直接对所有的查询客户机做出响应。尽管这种设计方式非常具有吸引力,但它不适用于当今的因特网,因为因特网有着数量巨大(并持续增长)的主机。这种集中式设计的问题包括: - 单点故障(a single point of failure):如果该DNS服务器故障,整个因特网将随之瘫痪
- 通信容量(traffic volume):单个DNS服务器不得不处理所有的DNS查询
- 远距离的集中式数据库(distant centralized database):查询的地理距离会导致严重的时延
- 维护(maintenance):在单一DNS服务器上运行集中式数据库完全没有可扩展能力
分布式、层次数据库
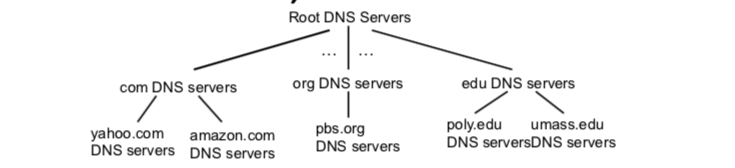
为了处理规模问题,DNS使用了大量的DNS服务器,它们以层次方式组织,并分布在全世界范围内。
有3种类型的DNS服务器: - 根服务器(root name servers)
- 顶级域(Top-level domain, TLD)服务器:
这些服务器负责顶级域名(如com、org、net、edu和gov)和所有国家的顶级域名(如uk、fr、ca和jp) - 权威DNS服务器(Authoritative DNS servers):
在因特网上具有公共可访问主机(如Web服务器和邮件服务器)的每个组织机构的权威DNS服务器负责保存这些记录。
假定一个DNS客户机要确定主机名www.amazon.com的IP地址。粗略来说将发生以下事件。该客户机首先与根服务器之一联系,它将返回顶级域名com的TLD服务器的IP地址。该客户机则与这些TLD服务器之一联系,它将为amazon.com返回权威服务器的IP地址。最后,该客户机为amazon.com联系权威服务器之一,他为主机名www.amazon.com返回IP地址。
还有另一类很重要的DNS,称为本地DNS服务器(local DNS server)。
本地服务器严格来说并不属于DNS服务器的层次结构,但它对DNS层次结构是很重要的。
主机的本地DNS服务器通常“临近”本主机。当主机发出DNS请求时,该请求被发往本地DNS服务器,它起着代理的作用,并将该请求转发到DNS服务器层次结构中。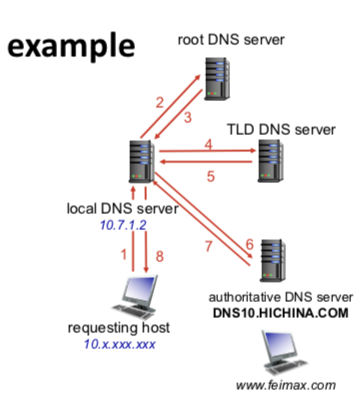
在本例中,为了获得一个主机名的映射,共发送了8份报文:4份查询报文和4份回答报文。
本例中也使用了递归查询(recursive query)和迭代查询(iterative query)。查询通常按照该例子中的模式:从请求主机到本地DNS服务器的查询是递归的,其余的查询是迭代的。
DNS缓存(DNS caching)
为了改善时延性能并减少在因特网上到处传输的DNS报文数量,DNS广泛使用了缓存技术。
在请求链中,当一个DNS服务器接收一个DNS回答(例如,包含主机名到IP地址的映射)时,DNS服务器能将回答中的信息缓存在本地存储器。如果在DNS服务器中缓存了一个主机名/IP地址对,另一个相同主机名的查询到达该DNS服务器时,该服务器能够提供所要求的IP地址,即使它不是该主机名的权威服务器。
由于主机和主机名与IP地址间的映射决不是永久的,所以DNS服务器在一段时间后(通常设置为两天)将丢弃缓存的信息。
本地DNS服务器也可以缓存TLD服务器的IP地址,因而允许本地DNS绕过查询链中的根服务器(这经常发生)。
DNS记录和报文
实现DNS分布式数据库的所有DNS服务器共同存储着资源记录(Resource Record, RR),RR提供了主机名到IP地址的映射。每个DNS回答报文包含了一条或多条资源记录。
资源记录是一个包含了下列字段的四元组:(Name, Value, Type, TTL)
TTL是该记录的生存时间,它决定了资源记录应当从缓存中删除的时间。
Name和Value的值取决于Type:
- 如果Type=A,则Name是主机名,Value是该主机名的IP地址。因此,一条类型为A的资源记录提供了标准的主机名到IP地址的映射。
- 如果Type=NS,则Name是域,而Value是知道如何获得该域中主机IP地址的权威DNS服务器的主机名,这个记录用于沿着查询链路进一步路由DNS查询。
- 如果Type=CNAME,则Value是别名为Name的主机对应的规范主机名
- 如果Type=MX,则Value是别名为Name的邮件服务器的规范主机名。MX记录允许邮件服务器的主机名具有简单的别名。通过使用MX记录,一个公司的邮件服务器和其他服务器(如它的Web服务器)可以使用相同的别名。为了获得邮件服务器的规范主机名,DNS客户机应当请求一条CNAME记录。
DNS报文
DNS只有查询和回复报文,并且,查询和回答报文有着相同的格式。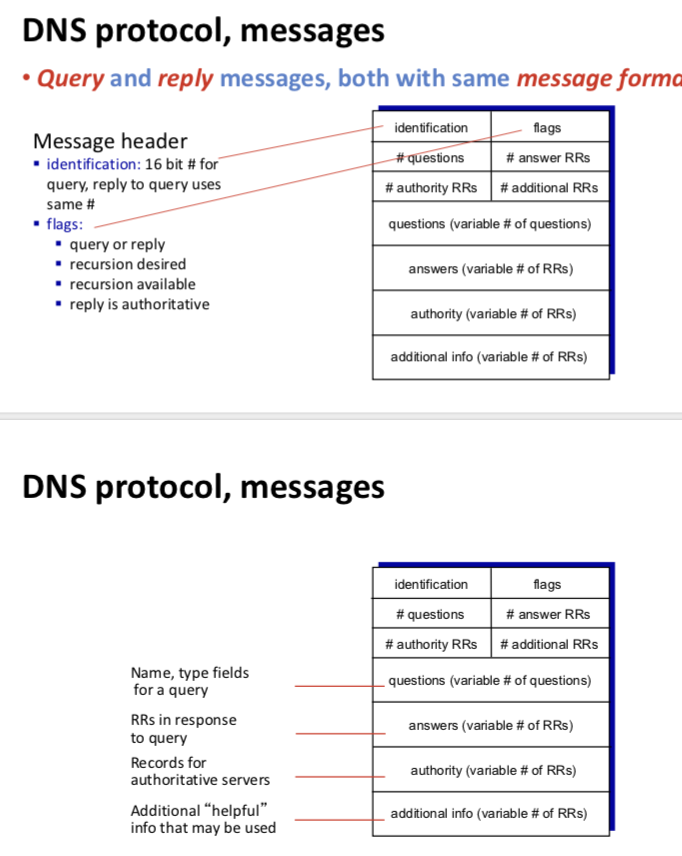
DNS报文中各字段的语义如下:
- 前12个字节是首部区域,其中有几个字段。
第一个字段是一个16比特的数,用于标示该查询。这个标识符会被复制到对查询的回答报文中,以便让客户机用它来匹配发送的请求和接收到的回答。标志字段中含有若干标志。
1比特的“查询/回答”标志位指出报文是查询报文(0)还是回答报文(1)。
在该首部还有4个“数量”字段,这些字段指出了在首部后4类数据区域出现的数量。 - 问题区域包含着正在进行的查询信息。该区域包括:1)名字字段,用于指出正在被查询的主机名字;2)类型字段,用于指出正被询问的问题类型。
- 在来自DNS服务器的回答报文中,回答区域包含了对最初请求的名字的资源记录。在一个回答报文的回答区域中可以包含多条RR,因为一个主机名可以对应多个IP地址。
- 权威区域包含了其他权威DNS服务器的记录
- 附加区域包含了一些其他有帮助的信息。
在DNS数据库中插入记录
首先要做的事情是在注册登记机构注册域名。注册登记机构(registrar)是一个商业实体,它验证域名的唯一性,将域名输入DNS数据库,对所提供的服务收取少量费用。
向某些注册登记机构注册域名的时候,需要向该机构提供你基本的权威DNS服务器和辅助权威DNS服务器的名字和IP地址。
你也必须确保用于Web服务器的类型A资源记录和用于邮件服务器的类型MX资源记录被输入你的权威DNS服务器中。
DNS攻击
- DDoS带宽洪泛攻击,攻击者能够向每个DNS根服务器连续不断地发送大量的分组,从而使大多数合法DNS攻击请求得不到回答。
- 更有效的DDoS攻击是向顶级域名服务器发送大量的DNS请求。这是因为更难过滤指向DNS服务器的DNS请求,并且顶级域名服务器不像根服务器那样容易被绕过
- 中间人攻击,攻击者截获来自主机的请求并返回伪造的回答。
- DNS毒害攻击,攻击者向DNS服务器发送伪造的回答,诱使服务器在其缓存中保存伪造的记录。3和4难以实现,因为他们要求截获分组或遏制服务器。
- 充分利用DNS基础设施来对目标主机发起DDoS攻击。在这种攻击中,攻击者向许多权威DNS服务器发送DNS请求,每个请求带有目标主机的假冒源地址。
P2P应用
P2P文件分发
我们通过讨论从单一服务器向大量主机(对等方)分发大文件这个应用来研究P2P
在客户机/服务器文件分发中,服务器必须向每个对等方发送该文件的一个拷贝,及服务器承担了极大的负担,并且消耗了大量的服务器带宽。
在P2P文件分发中,每个对等方都能够重新分发其所有的该文件的任何部分,从而协助服务器进行分发。
P2P体系结构的扩展性
我们假设服务器和对等方使用接入链路与因特网相连。其中$u_s$表示服务器接入链路的上载速率,$u_i$表示第$i$个对等方接入链路的下载速率。此外$F$表示被分发的文件长度(以比特计),$N$表示要获得文件拷贝的对等方的数量。
分发时间(distribution time)是$N$个对等方得到文件拷贝所需要的时间。我们可以根据课本上的推导(足够详细)得到
- 客户机/服务器体系结构中的分发时间我们取下界为实际分发时间,即
- 在P2P体系结构中,每个对等方都可以帮助服务器来分发文件,也就是说,当一个对等方接收到文件数据的时候,它可以利用自己的上载能力重新将数据分发给其他对等方。
P2P体系结构的分发时间我们取下界为实际的分发时间,即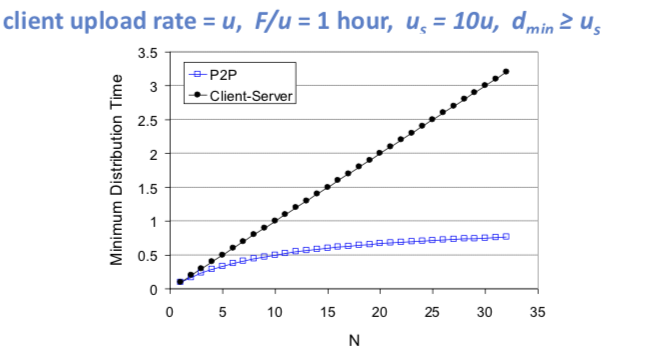
上图中我们设置了小时,, 。
对于客户机/服务器体系结构,随着对等方数量的增长,分发时间呈线性增长并且没有界。对于P2P体系结构,最小分发时间不仅总是小于客户机/服务器体系结构的分发时间,而且对任何多的对等方其总是小于1小时。因此采用P2P体系结构是可以拓展的,因为对等方除了是比特的消费者外还能重新分发。BitTorrent
BitTorrent是一种用于文件分发的流行P2P协议。用BitTorrent的术语来讲参与一个特定文件分发的所有对等方的一个集合称为一个洪流(torrent)。
在一个洪流中,对等方彼此下载等长度的文件块,块长度通常为256KB。
每个洪流具有一个基础设施节点,称为追踪器(tracker)。当一个对等方加入洪流时,它向追踪器注册,并周期性地通知追踪器它仍在洪流中。
当一个新的对等方Alice加入洪流时,追踪器随机地从参与对等方集合中选择一些对等方Alice持有对等方的这张列表,试图与该列表上的对等方创建并行的TCP连接。所有与Alice成功地创建连接的对等方为“临近对等方”,临近对等方将随着时间而改变。
在任何时刻,每个对等方都具有来自某文件块的自集。Alice周期性地(经TCP)连接询问每个临近对等方它们所具有的块列表,Alice将对她目前还没有的块发出请求(仍通过TCP连接)。
Alice将做出两个重要的决定: - 她应当向她的邻居请求哪些块呢?
Alice使用一种最稀罕优先(rarest first)的技术。这种技术的思路是:根据她没有的块从她的邻居中确定最稀罕的块(就是在她的邻居中拷贝数量最少的那些块),并优先请求那些最稀罕的块。 - 她请求的块应当发送给她的哪些邻居
为了决定Alice响应哪个请求,其基本想法是Alice确定其邻居的优先权,这些邻居是那些当前能以最高的速率给她数据的。
1】递归迭代?
2】分布式数据库
3】Type = NS?